文件异步Excel生成以及相关功能实现
以下代码都是直接在markdown上编辑的,均未通过编译,请根据逻辑自行编写代码
1. Excel文件异步生成
这个功能比较好实现,首先设计一下接口
/**
* 文件生成 - 根据数据查询条件导出数据
* @param infoEntity
* @return
*/
@PostMapping("/fileDataExportGen")
public Result fileDataExportGen(@RequestBody InfoEntity infoEntity){
String fileId = this.fileService.fileDataExportGen(infoEntity);
return Result.ok().put("body", fileId);
}
/**
* 文件生成状态查询
* @param fileId
* @return
*/
@PostMapping("/fileDataExportStatus")
public Result fileDataExportStatus(@RequestBody @NotNull(message = "文件标识不能为空") String fileId){
String status = this.fileService.fileDataExportStatus(fileId);
return Result.ok().put("body", status);
}
/**
* 文件下载
* @param fileId
* @return
*/
@GetMapping("/fileDownload")
public void fileDownload(@RequestParam @NotNull(message = "文件标识不能为空") String fileId, HttpServletResponse response) {
fileService.fileDownload(fileId, response);
}
这样可以通过 fileDataExportGen 接口申请通知后端生成文件,通过 fileDataExportStatus 查看文件生成情况,并通过 fileDownload 接口下载文件
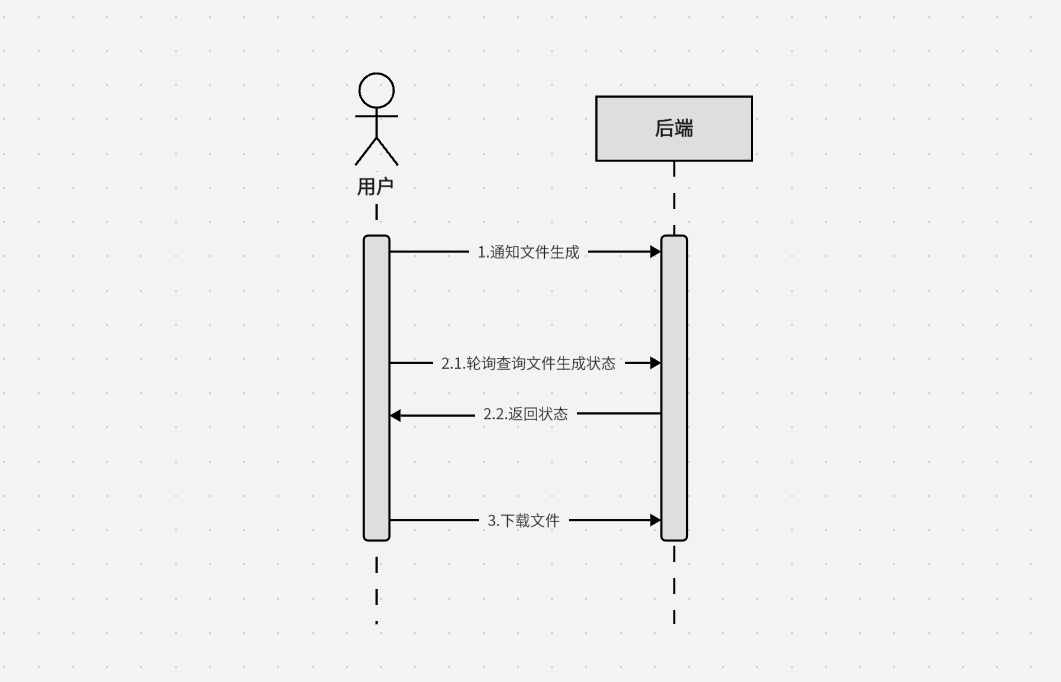
接下来省略service中fileDataExportStatus方法和fileDownload方法,在service中只需要定义一个Async方法,然后通过fileDataExportGen方法内调用即可(需要在Application类中添加@EnableAsync)
@Value("${demo.export.basePath:/home/demo/exportFile}")
private String basePath;
/**
* 生成文件
*/
public void fileDataExportGen(InfoEntity infoEntity){
InfoService bean = context.getBean(InfoService.class);
bean.startFileGenerate(infoEntity);
}
/**
* 异步方法 生成文件
*/
@Override
@Async
public void startFileGenerate(InfoEntity infoEntity) throws Exception {
List<JSONObject> list = dao.select(infoEntity);
List<HeadEntity> headers = dao.selectHeader();
String sheetName = "data";
try(Workbook workbook = new XSSFWorkbook()){
// 写入标题和数据
PoiUtil.createSheetByHeaderAndData(workbook, sheetName, headers, list);
// file存在本地或者对象存储
File file = PoiUtil.writeFile(workbook, basePath);
// TODO 对象存储
} catch(Exception e){
// throw
}
// TODO 状态更新
}
简单说明一下createSheetByHeaderAndData方法
public static void createSheetByHeaderAndData(Workbook workbook, String sheetName, List<HeadEntity> headers, List<JSONObject> list){
// 为空则默认赋值
if(Obejcts.isNull(workbook)){
workbook = new XSSFWorkbook();
}
Sheet sheet = workbook.getSheet(sheetName);
if(!Obejcts.isNull(workbook)){
// throw 指定名称的sheet页已经存在
}
sheet = workbook.createSheet(sheetName);
int lastRow = writeHeader(workbook, sheet, header);
writeData(workbook, sheet, header, list, lastRow);
}
这样一个比较简单的异步生成文件和下载的功能就实现了
2. 进度条实现(减少请求开销)
用户多次请求状态导致开销过大,于是考虑使用sse对生成过程进行实时反馈。
简单说明:sse类似于WebSocket,都是建立浏览器与服务器之间的通信渠道。WebSocket开销大,但是可以全双工通信,sse开销较小,只能服务器向浏览器推送信息。本质上就是以流信息的方式,完成一次用时很长的下载。
Controller:
/**
* 文件生成 - 根据数据查询条件导出数据
* @param infoEntity
* @return
*/
@PostMapping("/fileDataExportGen")
public SseEmitter fileDataExportGen(@RequestBody InfoEntity infoEntity){
// 返回SseEmitter实体
SseEmitter sseEmitter = this.fileService.fileDataExportGen(infoEntity);
return sseEmitter;
}
Service:
private final static Map<String, SseEmitter> sseEmitterMap = new ConcurrentHashMap<>();
/**
* 生成文件
*/
public SseEmitter fileDataExportGen(InfoEntity infoEntity){
// 生成实体,并创建唯一标识
String sseCode = UUID.randomUUID();
SseEmitter sseEmitter = new SseEmitter(60000L);
// 注册回调
sseEmitter.onCompletion(completionCallBack(sseCode));
sseEmitter.onError(errorCallBack(sseCode));
sseEmitter.onTimeout(timeoutCallBack(sseCode));
sseEmitterMap.put(sseCode, sseEmitter);
// 异步调用 startFileGenerate 方法
InfoService bean = context.getBean(InfoService.class);
bean.startFileGenerate(infoEntity, sseCode);
// 返回SseEmitter实体
return sseEmitter;
}
/**
* 异步方法 生成文件
*/
@Override
@Async
public void startFileGenerate(InfoEntity infoEntity, String sseCode) throws Exception {
SseEmitter sseEmitter = sseEmitterMap.get(sseCode);
String sheetName = "data";
try(Workbook workbook = new XSSFWorkbook()){
// 发送给前端 如有需要可以修改传送的结构
sseEmitter.send(sseCode);
sseEmitter.send("开始");
// 查询数据信息和标题信息
List<JSONObject> list = dao.select(infoEntity);
List<HeadEntity> headers = dao.selectHeader();
// 发送数据已经查询成功
sseEmitter.send("查询成功");
sseEmitter.send("共查询到" + list.size() + "条数据");
// 创建sheet
sheet = workbook.createSheet(sheetName);
// 写入表头
int lastRow = PoiUtil.writeHeader(workbook, sheet, header);
// 每写入100个,返回一次进度值
for (int i = 0; i < size; i += batchSize) {
List<JSONObject> batch = list.subList(i, endIndex);
PoiUtil.writeData(workbook, sheet, header, batch, i + lastRow);
sseEmitter.send("已写入" + i + "行数据");
}
// file存在本地或者对象存储
File file = PoiUtil.writeFile(workbook, basePath);
sseEmitter.send("写入完成");
// TODO 对象存储
} catch(Exception e){
// throw
} finally{
sseEmitter.complete();
sseEmitterMap.remove(sseCode);
}
// TODO 状态更新
}
这样可以直接通过sse返回进度,并让前端页面在获取信息后打印信息或者制作进度条以通知用户。当进度结束后前端可以直接提供按钮来访问 fileDownload 接口下载文件
从下一章开始不在详细阐述sse使用细节
3. SSE断联后重连机制
当因为用户误操作或者产品需求,需要在文件下载中拥有断联后重连机制。这个逻辑比较好实现,因为SSE是默认支持重连操作的。
但是还有个两个问题所在
-
按照第二章的代码分析,当用户断联的这段时间内,服务端发送的信息在客户端是无法捕获的,也就是说如果断联后发送的信息会丢失。
-
当用户断联后,服务端的SSE实例在完成,超时,报错时都会被注销,那么在注销后重连会获取不到任何信息
针对上述两个问题,生成对应方案:
版本号定义防止信息丢失
在每次发送信息时定义一个版本号,并临时储存版本号和发送的信息。版本号定义为:第一次版本号为0,此后每次信息发送时版本号原子性加一。
这样前端在获取到服务端发送的信息后将主要的sseCode和version存到localStorage中,当刷新页面后如果获取到了相关信息,则访问重连接口,重连接口会根据version重新发送之后的所有信息。
Controller:
/**
* 文件生成 - 根据数据查询条件导出数据
* @param sseCode
*/
@GetMapping("/reConnect")
public SseEmitter reConnect(@RequestParam String sseCode){
SseEmitter sseEmitter = this.fileService.reConnect(sseCode);
return sseEmitter;
}
Service:
// 模拟存储每个客户端的最新版本号
private Map<String, Integer> clientVersions = new HashMap<>();
// 模拟存储所有信息
private List<String> allMessages = new ArrayList<>();
/**
* 文件生成 - 根据数据查询条件导出数据
*/
public SseEmitter reConnect(String sseCode){
SseEmitter sseEmitter = SseEmitterUtil.get(sseCode);
// 获取客户端的最后版本号,如果不存在则默认为 0
int lastVersion = clientVersions.getOrDefault(sseCode, 0);
// 获取断联后丢失的信息
List<String> lostMessages = getLostMessages(lastVersion);
// 发送丢失的信息
sendMessages(sseEmitter, lostMessages);
// 更新客户端的版本号
clientVersions.put(sseCode, allMessages.size());
// 处理 SseEmitter 的完成、超时和错误事件
sseEmitter.onCompletion(completionCallBack(sseCode));
sseEmitter.onError(errorCallBack(sseCode));
sseEmitter.onTimeout(timeoutCallBack(sseCode));
sseEmitterMap.put(sseCode, sseEmitter);
return sseEmitter;
}
可以将数据存入redis中并设置超时时间,在超时时间内都可以获取信息。
4. 数据量过大的处理方式(流式查询 + excel刷盘写入)
如果遇到数据量过大的情况(假设百万条以上的数据),那要考虑的问题就比较多
-
不能全量读取所有数据到内存中,这样会导致内存溢出。
-
不能通过数据库分页功能实现部分读取,因为这种操作在插入/更新/删除数据操作时会影响到结果集的查询
-
写入excel时需要做临时文件处理,这样也是为了防止内存溢出
-
数据量大导致导出时间过长,需要多线程处理
于是通过特殊的流式查询加刷盘已达到资源占用量小,还可以保证数据输出的完整性
流式查询
通过ResultHandler ,将查询结果以迭代器形式逐行返回,而非一次性加载到内存
实现步骤如下:
Mapper:
// 具体sql在xml中实现,fetchSize代表从数据库请求一次返回多少条数据,数据量越大,占用内存越多,但是请求的开销越少
@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000)
void selectByResultHandler(ResultHandler<InfoEntity> handler);
自定义 ResultHandler:
public class DataHandler implements ResultHandler<InfoEntity> {
private static final int BATCH_SIZE = 100;
private List<InfoEntity> buffer = new ArrayList<>();
private final Workbook workbook;
private int lastRow;
private String basePath;
private String sseCode;
// 构造函数接收 Workbook 对象
public ExcelResultHandler(Workbook workbook, int lastRow, String basePath, String sseCode) {
this.workbook = workbook;
this.lastRow = lastRow;
this.basePath = basePath;
this.sseCode = sseCode;
}
@Override
public void handleResult(ResultContext<? extends InfoEntity> resultContext) {
InfoEntity infoEntity = resultContext.getResultObject();
buffer.add(infoEntity);
if (buffer.size() >= BATCH_SIZE) {
processBatch(buffer); // 执行批量操作
buffer.clear();
SseEmitter.send(sseCode, lastRow);
}
}
// 处理剩余数据(最后一次可能不足 BATCH_SIZE)
public void finalize() {
if (!buffer.isEmpty()) {
processBatch(buffer);
}
File file = PoiUtil.writeFile(workbook, basePath);
}
private void processBatch(List<InfoEntity> infoEntity) {
PoiUtil.writeData(workbook, sheet, header, batch, lastRow);
lastRow += infoEntity.size();
}
}
最后在Service上调用
@Value("${demo.export.basePath:/home/demo/exportFile}")
private String basePath;
public void exportToExcel(String sseCode, HttpServletResponse response) {
response.setHeader("Content-Disposition", "attachment;filename=data.xlsx");
try (SXSSFWorkbook workbook = new SXSSFWorkbook(100)) {
// 创建sheet
sheet = workbook.createSheet(sheetName);
// 写入表头
int lastRow = PoiUtil.writeHeader(workbook, sheet, header);
// 创建handler
ResultHandler<InfoEntity> handler = new DataHandler<>(workbook, lastRow, basePath, sseCode);
// 开始查询
infoMapper.selectByResultHandler(handler);
}
}
如此完成流式查询。
异步刷盘分块写入
Apache POI 的 SXSSFWorkbook,实现 Excel 流式写入,其底层机制是 内存缓存+磁盘临时文件。
例如设置 rowAccessWindowSize=100 表示仅保留 100 行数据在内存中,超出部分自动写入临时文件,显著降低内存占用。
其实在上面的代码中,已经使用了 SXSSFWorkbook ,并设定了rowAccessWindowSize,这样 SXSSFWorkbook 就可以实现自动刷盘。
如果想做到手动刷盘可以这么做
SXSSFWorkbook workbook = new SXSSFWorkbook(100);
Sheet sheet = workbook.createSheet("Data");
// 逐行读取并写入
int rowNum = 0;
Iterator<Data> iterator = cursor.iterator();
while (iterator.hasNext()) {
Data data = iterator.next();
Row row = sheet.createRow(rowNum++);
row.createCell(0).setCellValue(data.getId());
row.createCell(1).setCellValue(data.getName());
// 每写入 1000 条刷盘一次
if (rowNum % 1000 == 0) {
((SXSSFSheet) sheet).flushRows(1000); // 强制刷盘
workbook.write(tempOutputStream); // 写入临时文件
if(rowNum % 200000){
sheet = workbook.createSheet("Data_" + (rowNum / 200000)); // 分 Sheet 写入(可选)
}
}
}
// 最终刷盘并保存文件
workbook.write(finalOutputStream);
workbook.dispose(); // 清理临时文件
此方法可以同时做到分sheet页,保证一个sheet页存储20万条数据
多线程写入文件
实际上 SXSSFWorkbook 本身并不是线程安全的类,ResultHandler默认也是在单线程中被调用。异步生成文件的目的就是让用户对长时间的数据处理减少反感,所以在需求不强烈的情况下还是建议单线程处理。如果想要做到多线程可以用以下两个办法:
-
在ResultHandler内启用线程将数据插入SXSSFWorkbook,同时对SXSSFWorkbook做好同步机制,这样在操作SXSSFWorkbook时可以继续对数据进行读取。
-
使用阻塞队列解耦数据读取与写入,ResultHandler将数据批次放入队列,独立线程从队列取出批次并写入Excel。
5. 文件定期删除(redis超时过期 + 定时清理)
如果是将文件存入对象存储中,那只需要设置过期时间即可,但是如果是存在本地,那需要方法来定期删除。
比较保险的方法就是通过 redis超时过期 + Scheduled定时清理 ,已达到文件的清理逻辑完整性
redis超时过期
实现 redis超时过期 ,在文件生成结束后将文件属性等信息存入redis中并设置过期时间,到期后会自动调用 onMessage 方法来清理文件。
@Slf4j
@Component
public class FileGenExpirationListener extends KeyExpirationEventMessageListener {
@Value("${demo.export.basePath:/home/demo/exportFile")
private String basePath ;
@Value("${demo.export.redisPrefix:file}")
private String redisPrefix;
@Value("${demo.export.redisExpireSeconds:300}")
private int redisExpireSeconds;
@Autowired
public FileGenExpirationListener(RedisMessageListenerContainer listenerContainer) {
super(listenerContainer);
}
/**
* 生成文件过期删除
* @param message
* @param pattern
*/
@Override
public void onMessage(Message message, byte[] pattern) {
String expiredKey = message.toString();
// 假设 key 的格式为 "file:文件路径"
if (expiredKey.startsWith(redisPrefix)) {
String filePath = basePath + "/" + expiredKey.replace(redisPrefix + ":", "") + ".xlsx";
deleteFile(filePath);
}
}
/**
* 删除文件
* @param path
*/
private void deleteFile(String path) {
deleteFile(new File(path));
}
/**
* 删除文件
* @param file
*/
private void deleteFile(File file) {
if (file.exists() && file.isFile()) {
if (file.delete()) {
log.info("生成文件过期删除成功:{}", file.getAbsolutePath());
} else {
log.error("生成文件过期删除失败:{}", file.getAbsolutePath());
}
}
}
}
需要注意的是redis需要支持键空间通知功能
notify-keyspace-events Ex
定时清理
使用Scheduled注解, 每30分钟扫描一次指定basePath路径下所有超过指定时间的.xlsx文件,这样可以删除当服务因某些原因停止运行导致无法通过redis到期机制删除的文件。
/**
* 定时查看文件生成路径下的文件是否超时失效,并对失效文件删除
*/
@Scheduled(fixedRate = 30 * 60 * 1000)
public void checkExpiredFiles() {
try {
Path dirPath = Paths.get(basePath);
if (!Files.exists(dirPath) || !Files.isDirectory(dirPath)) {
System.err.println("目录不存在或不是有效文件夹: " + basePath);
return;
}
Files.walk(dirPath)
.filter(Files::isRegularFile)
.forEach(file -> {
try {
BasicFileAttributes attrs = Files.readAttributes(file, BasicFileAttributes.class);
LocalDateTime lastModifiedTime = LocalDateTime.ofInstant(
attrs.lastModifiedTime().toInstant(),
ZoneId.systemDefault()
);
LocalDateTime cutoffTime = LocalDateTime.now().minusSeconds(redisExpireSeconds);
String name = file.getFileName().toString();
String extension = name.substring(name.lastIndexOf("."));
if (lastModifiedTime.isBefore(cutoffTime) && BusConstant.EXCEL_EXT_XLSX.equalsIgnoreCase(extension)) {
deleteFile(file.toFile());
}
} catch (IOException e) {
// throw
}
});
} catch (IOException e) {
// throw
}
}